Transformer-Konfiguration für Stammdaten-Importe
Diese Anleitung beschreibt, wie Sie in der Workbench die Transformer-Konfiguration eines Stammdaten-Imports einsehen und anpassen. Die Transformer-Konfiguration bestimmt, welche Datei vom SFTP-Server (oder aus einem datei-basierten API-Upload) gelesen wird, wie sie eingelesen wird (Codierung, Trennzeichen, …) und wie die Spalten Ihrer Datei auf das von Workist erwartete Zielschema abgebildet werden.
Jede Lookup-Definition (Artikel, Kunden, Kundenkontakte, Adressen, Umrechnungsfaktoren, Rahmenverträge, Bestellabgleich, Angebotsabgleich) hat eine eigene Transformer-Konfiguration.
Voraussetzungen
- Ein Workbench-Konto mit Zugriff auf die Stammdaten-Importe des jeweiligen Kanals.
- Eine bereits eingerichtete Lookup-Definition mit mindestens einem vorhandenen Stammdaten-Import. Die Konfiguration lässt sich nur über eine bestehende Import-Zeile öffnen.
- Mindestens eine Beispieldatei, deren Spaltennamen Sie kennen — sonst können Sie die Zuordnung auf das Zielschema nicht vornehmen.
Die Transformer-Konfiguration steuert das Einlesen der Datei nur dann, wenn kein kundenspezifisches Transformer-Skript hinterlegt ist. Bei kundenspezifischen Skripten beschränken sich die wirksamen Felder meist auf Dateinamensmuster und ausgewählte Parameter — der Spaltenausdruck wird in diesem Fall ignoriert.
Schritt 1 — Stammdaten-Importe öffnen
Wechseln Sie in der Workbench zu dem Kanal, dessen Stammdaten Sie konfigurieren möchten (z. B. ein Bestellungs- oder Rechnungskanal) und öffnen Sie über die Navigation den Bereich Stammdatenimporte.
Sie sehen eine tabellarische Übersicht aller bisherigen Importläufe je Lookup-Typ (Artikel, Adressen, Kunden, …) mit Status, Dauer und Verweis auf die ein- und ausgehenden Dateien.
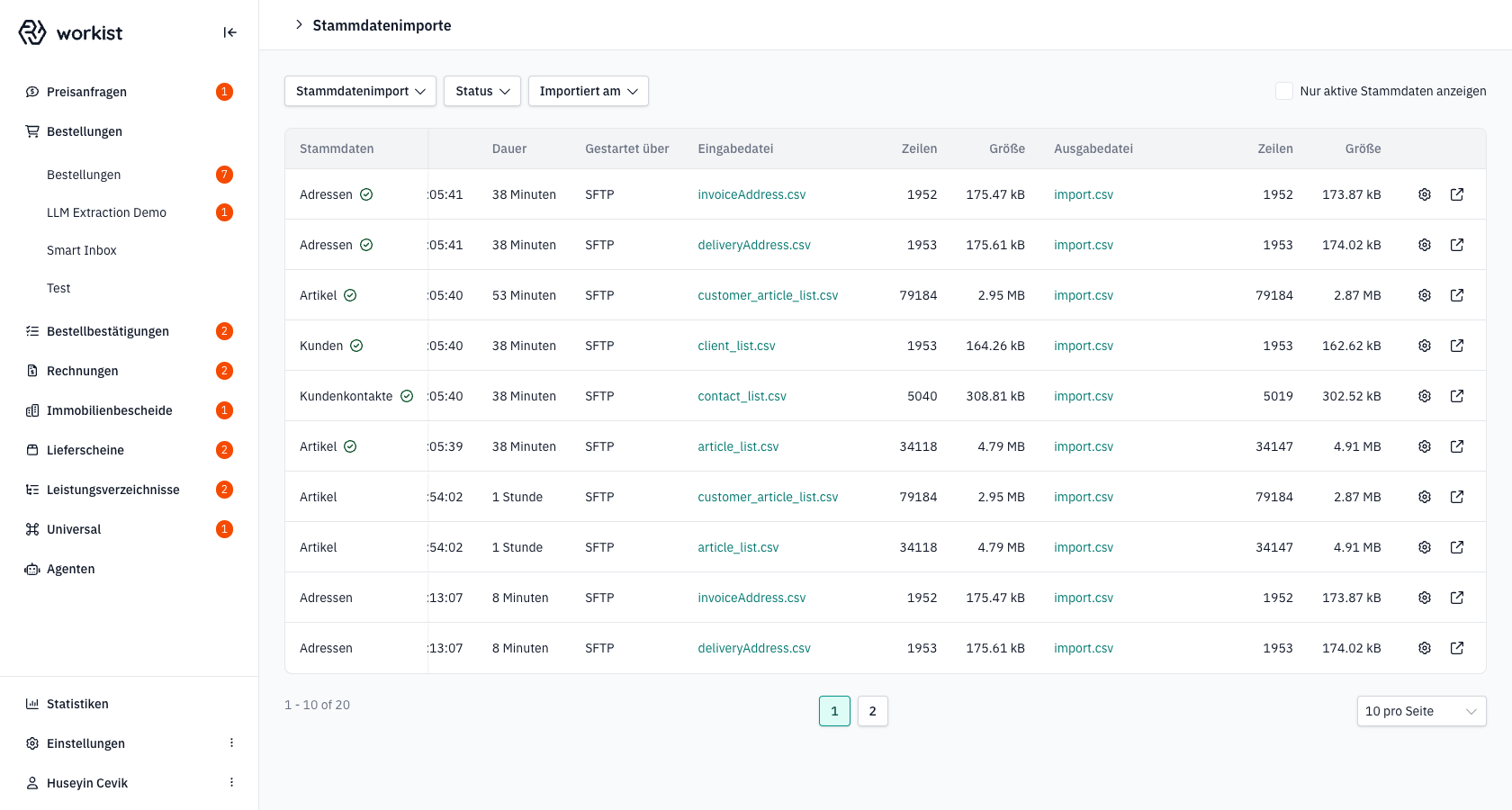
Ganz rechts in jeder Zeile finden Sie ein Zahnrad-Symbol (Import konfigurieren). Klicken Sie auf das Zahnrad in der Zeile des Lookup-Typs, dessen Konfiguration Sie ändern möchten.
Noch kein Import gelaufen? Solange für einen Lookup-Typ kein Import-Lauf existiert, ist die Tabelle Stammdatenimporte für diesen Typ leer und es gibt dort keine Zeile mit Zahnrad. Öffnen Sie in diesem Fall stattdessen die Kanal-Konfiguration → Stammdaten und klicken Sie auf das Zahnrad neben der Schaltfläche „Datei hochladen" des betreffenden Lookup-Typs — Sie landen im selben Konfigurationsdialog.
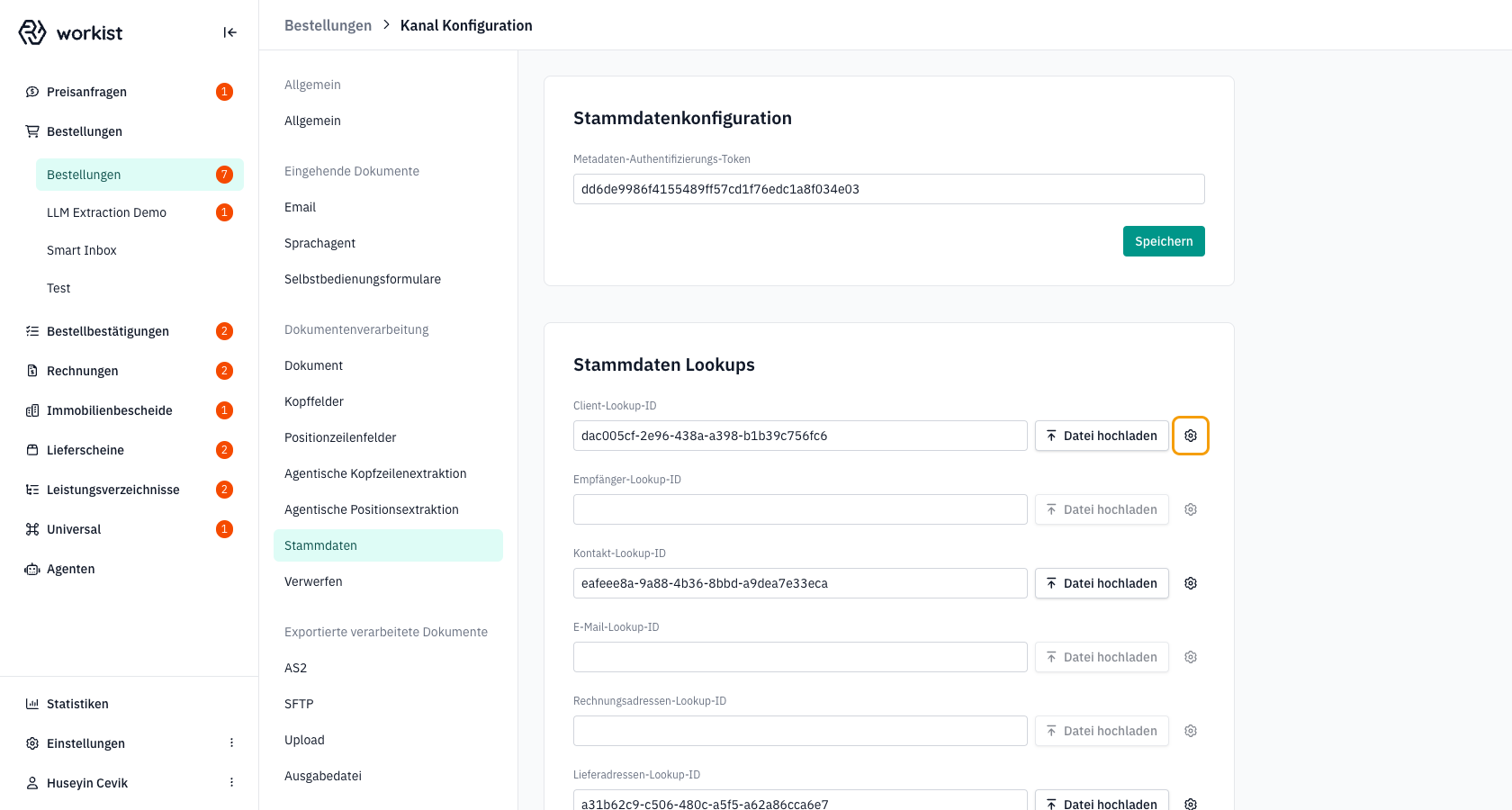
Schritt 2 — Den Dialog „Konfiguration importieren" verstehen
Es öffnet sich der Dialog Konfiguration importieren. Er hat zwei Reiter:
- Formular — geführte Eingabe für die häufigsten Felder. Eingaben werden gegen das Zielschema des jeweiligen Lookup-Typs geprüft.
- Rohes JSON — direkter Zugriff auf die komplette Transformer-Konfiguration. Hier können Sie auch Felder konfigurieren, die im Formular nicht erscheinen (z. B.
apply_common_functions,query,replace_nan).
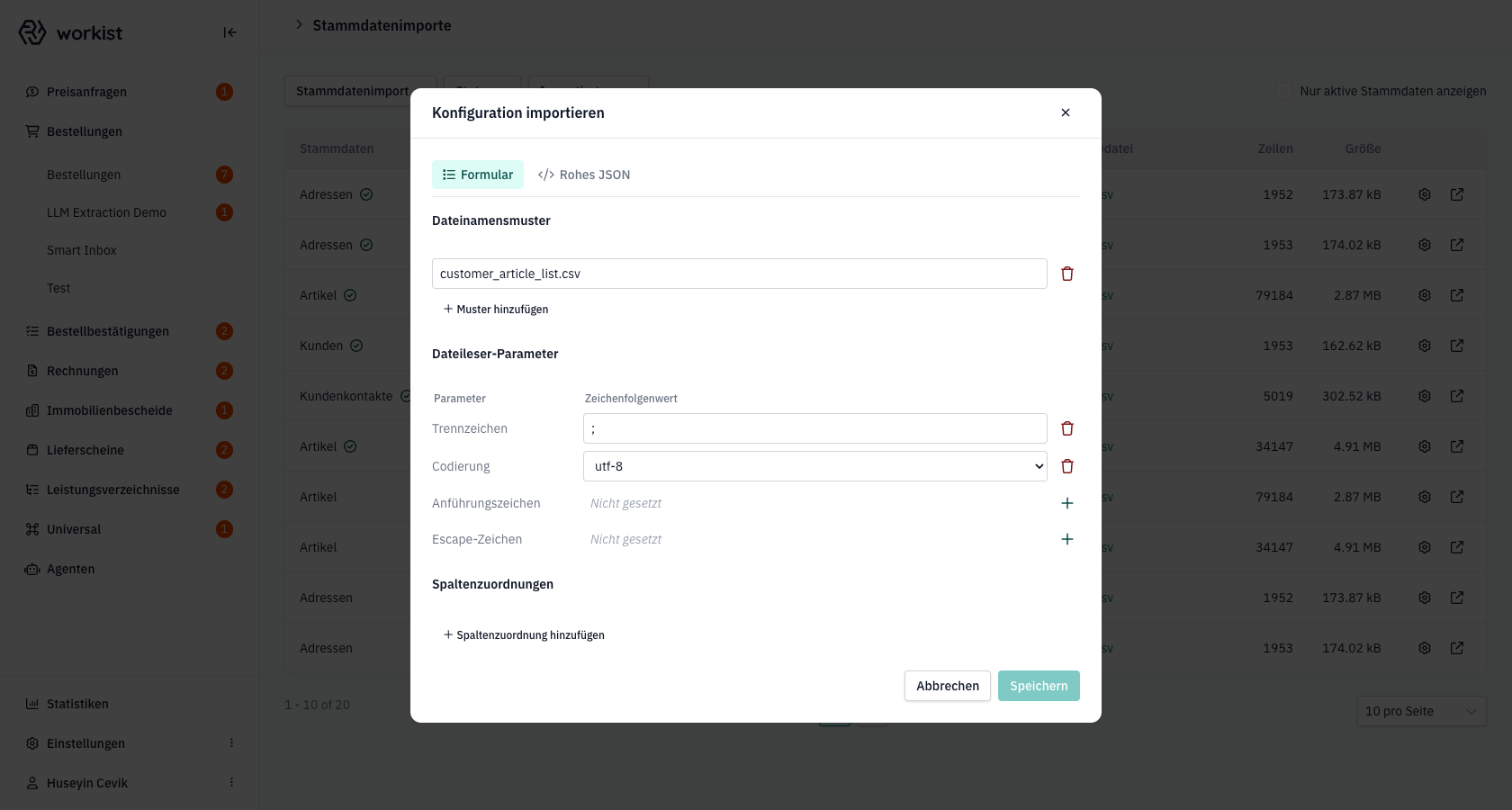
Der Formular-Reiter ist in drei Bereiche unterteilt:
- Dateinamensmuster — welche Datei(en) auf dem SFTP-Server für diesen Import gelesen werden sollen.
- Dateileser-Parameter — wie die Datei eingelesen wird (Trennzeichen, Codierung, …).
- Spaltenzuordnungen — wie die Spalten Ihrer Datei auf die Spalten des Workist-Zielschemas abgebildet werden.
Schritt 3 — Dateinamensmuster
Im Abschnitt Dateinamensmuster legen Sie fest, welche Dateien auf Ihrem SFTP-Export-Verzeichnis als Eingabe für diesen Import gelten.
- Sie können einen festen Dateinamen eintragen, z. B.
customer_article_list.csv. - Wildcards sind erlaubt, z. B.
*.csvoderarticles_*_full.csv. - Mit + Muster hinzufügen lassen sich mehrere Muster eintragen.
Wenn mehrere Muster eingetragen sind, wird der Import jedes Mal ausgelöst, sobald eine Datei mit einem passenden Muster eingeht.
Verwenden Sie möglichst restriktive Muster. Ein zu breites Muster wie *.csv kann dazu führen, dass artikelfremde Dateien versehentlich als Artikelliste interpretiert werden.
Schritt 4 — Dateileser-Parameter
Im Abschnitt Dateileser-Parameter stellen Sie ein, wie Workist Ihre Datei einlesen soll. Jede Zeile wird über das Plus-Symbol (+) aktiviert und über das Mülleimer-Symbol wieder entfernt. Standardwerte gelten, solange ein Parameter nicht gesetzt ist.
| Parameter | Bedeutung | Beispiel |
|---|---|---|
| Trennzeichen | Spaltentrenner in CSV-Dateien. Wird standardmäßig automatisch erkannt. | ; , \t |
| Codierung | Zeichensatz der Datei. Standard ist UTF-8. | utf-8, latin-1, cp1252 |
| Anführungszeichen | Zeichen, mit dem Werte in der CSV-Datei eingefasst sind. | " oder ' |
| Escape-Zeichen | Zeichen zum Maskieren des Anführungszeichens innerhalb eines Wertes. | \ |
Für Excel-Dateien (.xls, .xlsx) werden diese Parameter ignoriert — Workist erkennt das Format anhand der Dateiendung und liest die Tabelle direkt ein.
Schritt 5 — Spaltenzuordnungen
Im Abschnitt Spaltenzuordnungen ordnen Sie die Spalten Ihrer Eingabedatei den Spalten des Workist-Zielschemas zu. Beim ersten Hinzufügen werden die Pflichtspalten des jeweiligen Lookup-Typs automatisch eingefügt und mit einem * gekennzeichnet — sie können nicht entfernt werden.
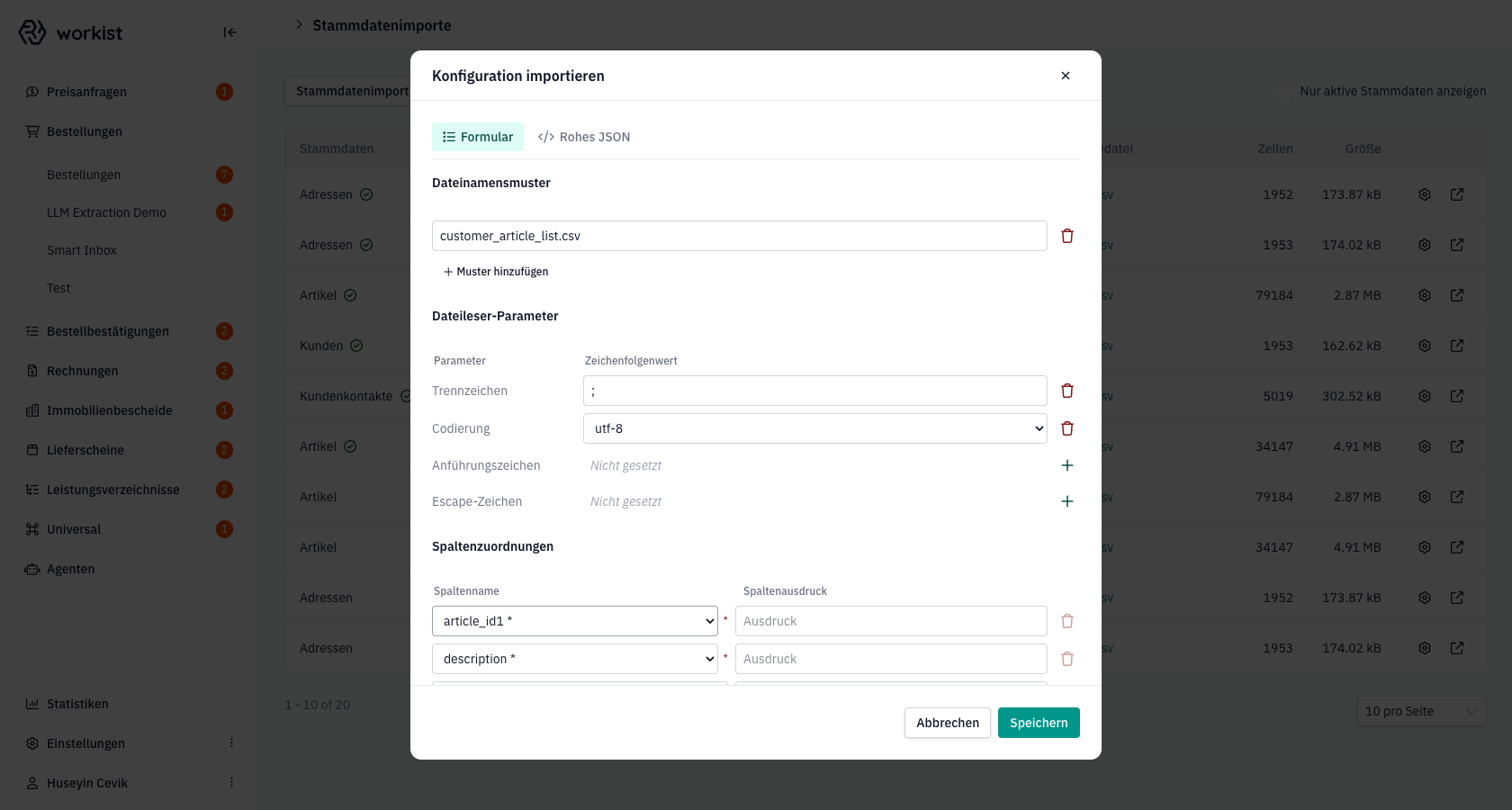
Jede Zeile besteht aus zwei Feldern:
-
Spaltenname — der Zielname (Workist-Schema), aus einer Liste der erlaubten Spalten des aktuellen Lookup-Typs.
-
Spaltenausdruck — woher der Wert kommt. Hier sind vier Ausdrucksarten möglich:
Ausdruck Bedeutung ArtikelnummerDirekte Spaltenreferenz — der Wert wird 1:1 aus der gleichnamigen Spalte übernommen. {Bezeichnung1} {Bezeichnung2}Vorlagen-Ausdruck — Platzhalter in geschweiften Klammern werden durch Spaltenwerte ersetzt. 'STK'Stringliteral — der Wert wird fest hinterlegt (z. B. eine konstante Einheit). (leer) Leere Spalte — eine neue, leere Zielspalte wird angelegt. PASSBeibehalten, wenn vorhanden — die gleichnamige Spalte wird durchgereicht; ist sie nicht da, wird die Zuordnung ignoriert.
Beispiel für eine Artikelliste:
| Spaltenname | Spaltenausdruck |
|---|---|
article_id1 * | Artikelnummer |
description * | {Bezeichnung_DE} {Farbe} |
partition_id | 'main' |
gross_price | Listenpreis |
order_units | Bestelleinheit |
Spalten, die in Ihrer Eingabedatei vorhanden sind, im Workist-Schema aber nicht erlaubt sind, werden mit einem orangefarbenen ! gekennzeichnet — sie werden später beim Import ignoriert.
Mit + Spaltenzuordnung hinzufügen lassen sich weitere Zuordnungen ergänzen, bis alle Spalten des Zielschemas verwendet sind. Über das Mülleimer-Symbol kann jede optionale Zuordnung wieder entfernt werden.
Schritt 6 — Reiter „Rohes JSON" für fortgeschrittene Felder
Über den Reiter Rohes JSON sehen Sie die komplette Transformer-Konfiguration als JSON-Dokument und können sie direkt bearbeiten.
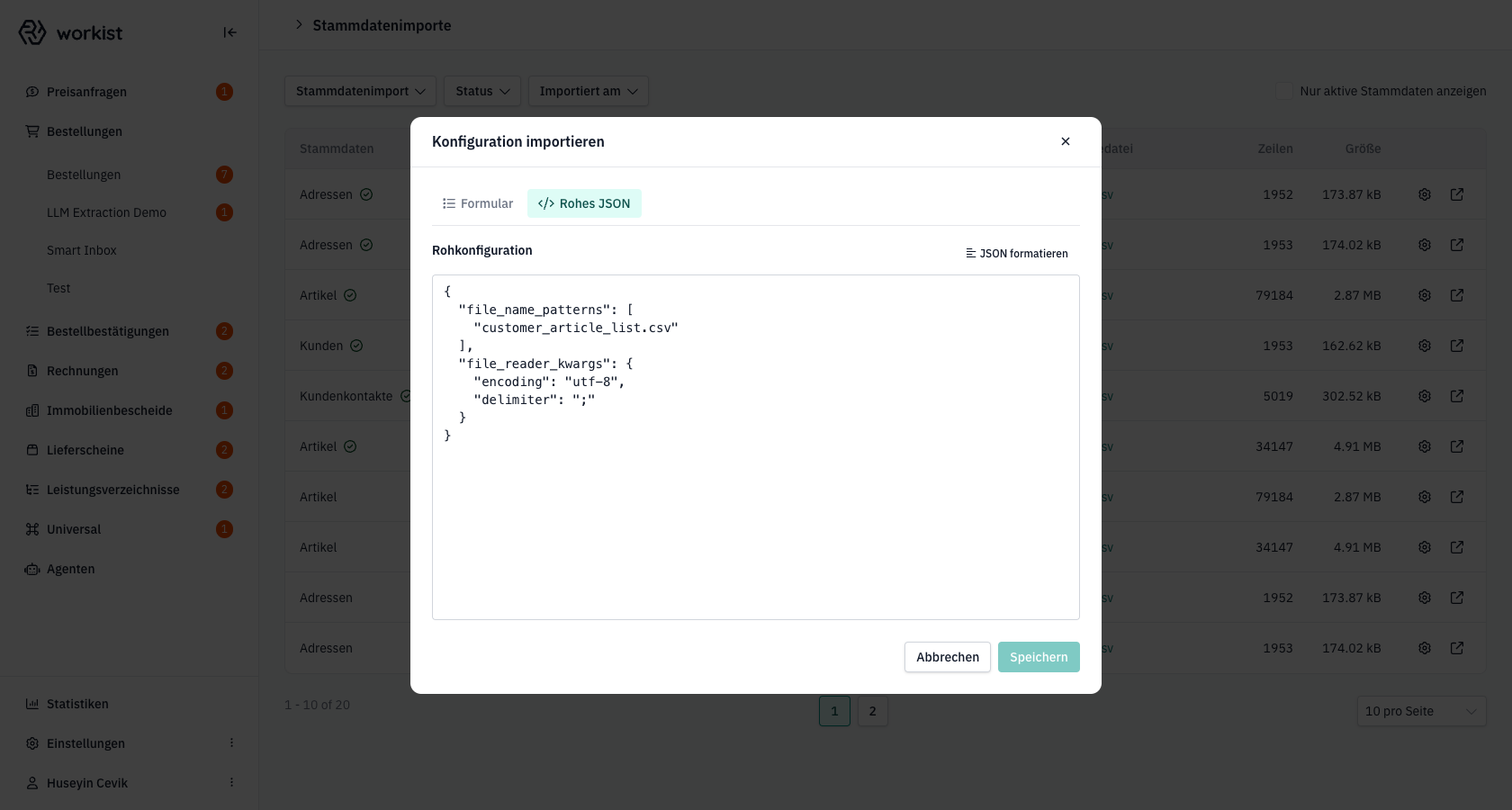
Im JSON-Reiter sind insbesondere Felder verfügbar, die im Formular nicht angezeigt werden:
apply_common_functions— eine Liste vordefinierter Transformationen, die in der angegebenen Reihenfolge auf die Datei angewendet werden, z. B.:query— Zeilen anhand einer Bedingung herausfiltern ("query": "source_unit != target_unit").strip— führende und folgende Leerzeichen entfernen.drop_column— eine Spalte aus dem Ergebnis entfernen.remove_duplicated_rows— doppelte Zeilen entfernen.remove_leading_zeros— führende Nullen in einer Spalte abschneiden (häufig bei Artikelnummern).set_default_order_unit/set_default_order_unit_to_sales_unit/ensure_sales_unit_in_order_unit— Bestelleinheiten standardisieren.eval_expression— einen Ausdruck zur Berechnung eines neuen Spaltenwerts auswerten (z. B. zusammengesetzte Kundenbezeichnung).add_incremental_id— eine fortlaufende ID als Spalte hinzufügen.filter_by_length/detect_chars— Zeilen anhand der Länge oder eines Musters in einer Spalte filtern.
replace_nan— leere Werte einer Spalte durch einen Standardwert ersetzen.query— globale Filter-Bedingung, die direkt nach dem Einlesen ausgewertet wird.
Beispiel-JSON für eine Artikelliste mit Pflicht-Pflege:
{
"file_name_patterns": ["customer_article_list.csv"],
"file_reader_kwargs": {
"encoding": "utf-8",
"delimiter": ";"
},
"columns": {
"article_id1": "Artikelnummer",
"description": "{Bezeichnung_DE} {Farbe}",
"partition_id": "'main'",
"gross_price": "Listenpreis",
"order_units": "Bestelleinheit",
"sales_units": "Verkaufseinheit"
},
"apply_common_functions": [
{ "strip": "description" },
{ "remove_leading_zeros": "article_id1" },
{ "remove_duplicated_rows": ["article_id1"] }
]
}
Sobald Sie etwas am JSON ändern, erscheint unten ein roter Hinweis, falls das JSON syntaktisch nicht gültig ist. Über JSON formatieren lässt sich der Text einrücken und ordnen, ohne den Inhalt zu verändern.
Die Spaltennamen auf der linken Seite von "columns" müssen aus dem Zielschema des jeweiligen Lookup-Typs stammen — andernfalls wird die Konfiguration beim Speichern abgelehnt.
Schritt 7 — Speichern
Klicken Sie unten rechts auf Speichern. Im Erfolgsfall schließt sich der Dialog nicht; stattdessen wird die Anzeige aktualisiert und Sie sehen die gespeicherte Konfiguration. Mit Abbrechen verwerfen Sie alle Änderungen seit dem letzten Speichern.
Erst beim nächsten Import-Lauf. Bereits abgeschlossene Importe werden nicht rückwirkend neu verarbeitet. Soll die neue Konfiguration sofort wirken, laden Sie die Eingabedatei nach dem Speichern erneut auf den SFTP-Server hoch oder lösen Sie den Import bei Ihrer Ansprechperson bei Workist erneut aus.
Pro Lookup-Typ erlaubte Zielspalten
Welche Spalten im Spaltenname-Feld zur Auswahl stehen, hängt vom Lookup-Typ ab. Die wichtigsten Schemata im Überblick (Pflichtspalten in fett):
| Lookup-Typ | Pflichtspalten | Wichtige optionale Spalten |
|---|---|---|
| Artikel | article_id1, description | article_id2, article_id3, gross_price, order_units, sales_units, partition_id, article_status, extra_data |
| Kunden | client_id1 | company_name, address1, street_name, zip_code, city, country, iln, vat, iban, partition_id |
| Kundenkontakte | partition_id, contact_id, first_name, last_name | email, phone, extra_data |
| Adressen | address_id1 | name, address1, street_name, zip_code, city, country, phone, partition_id |
| Umrechnungsfaktoren | source_unit, target_unit, conversion_quotient | article_id, partition_id |
| Rahmenverträge | partition_id, contract_id1 | client_id, client_name, contract_id2, contract_name |
| Bestellabgleich | order_number | order_date, delivery_address, article_id1, quantity, total_price, payment_terms_due_days, iban |
| Angebotsabgleich | offer_number | valid_from, valid_until, article_id1, quantity, unit |
Spalten außerhalb dieser Listen werden vom Importpfad abgelehnt.
Hilfe und Support
Wenn der Import nach einer Änderung weiterhin scheitert oder die gewünschten Werte nicht im Workist-Schema landen, wenden Sie sich an Ihre Ansprechperson bei Workist und halten Sie die folgenden Informationen bereit:
- den Kanalnamen und den Lookup-Typ (z. B. „Artikel"),
- den Zeitpunkt des fehlgeschlagenen Imports (Spalte Importiert am),
- die Eingabedatei des Imports (in der Tabelle verlinkt),
- bei Anpassungen am JSON: das vollständige JSON-Dokument aus dem Reiter Rohes JSON.